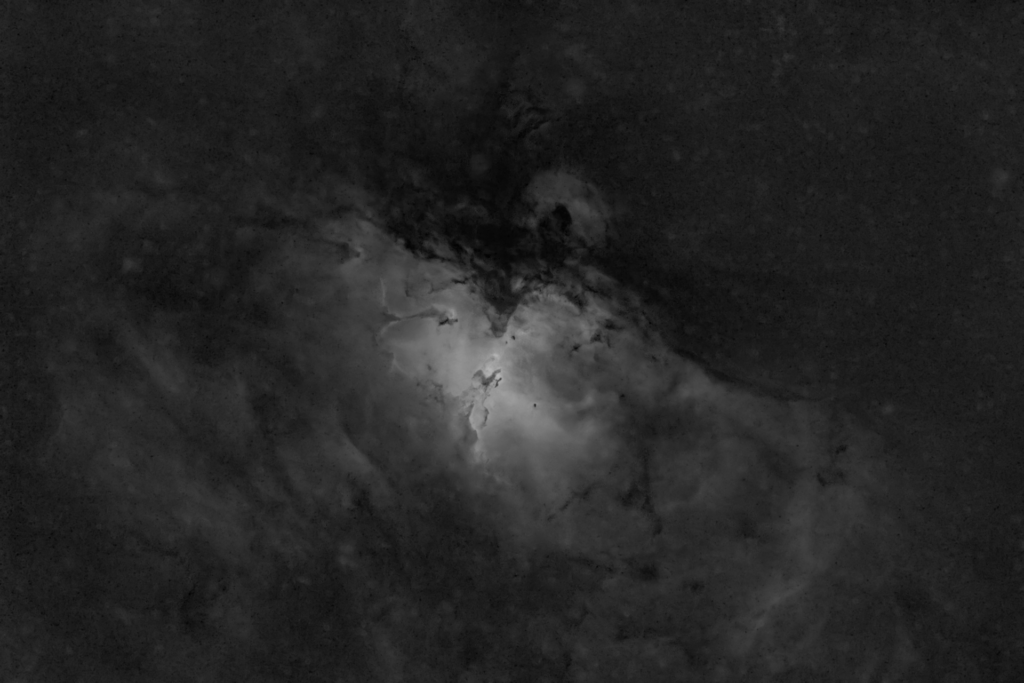



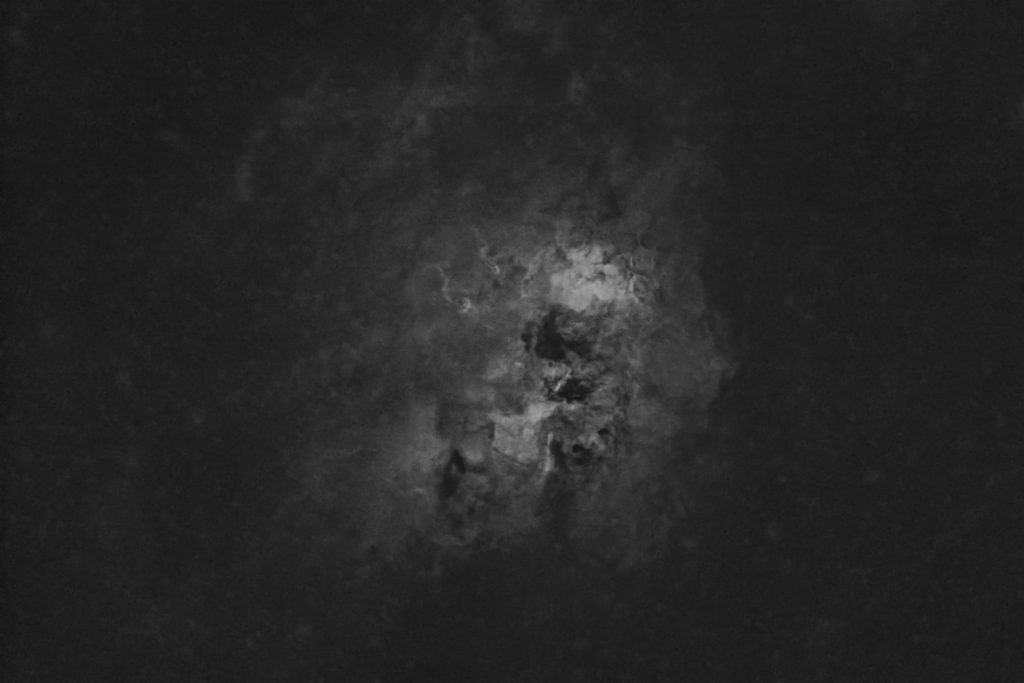

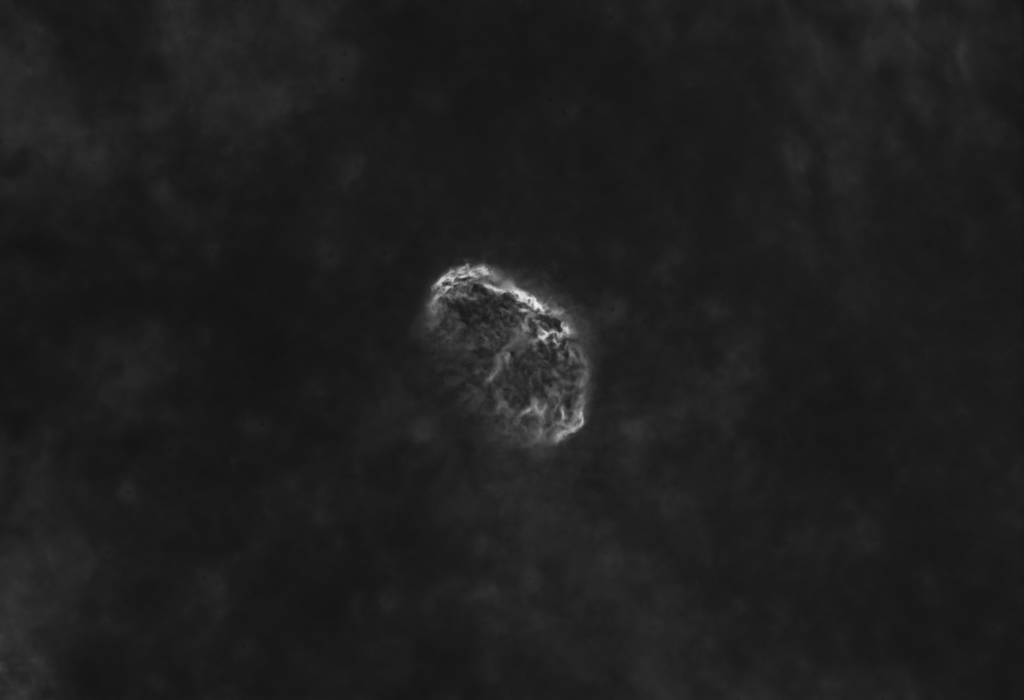



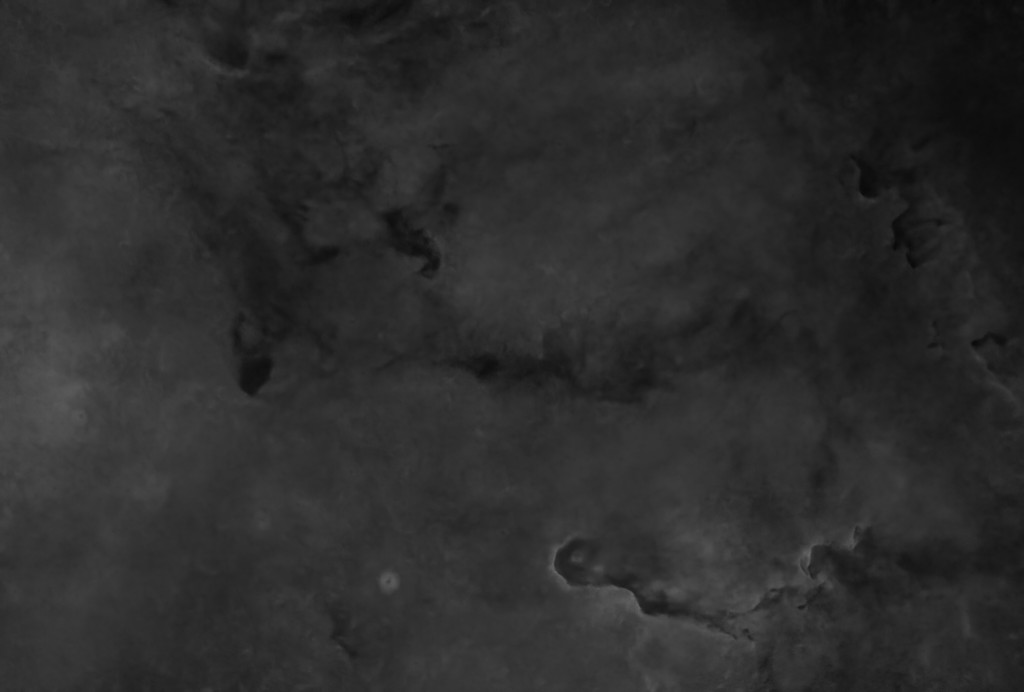

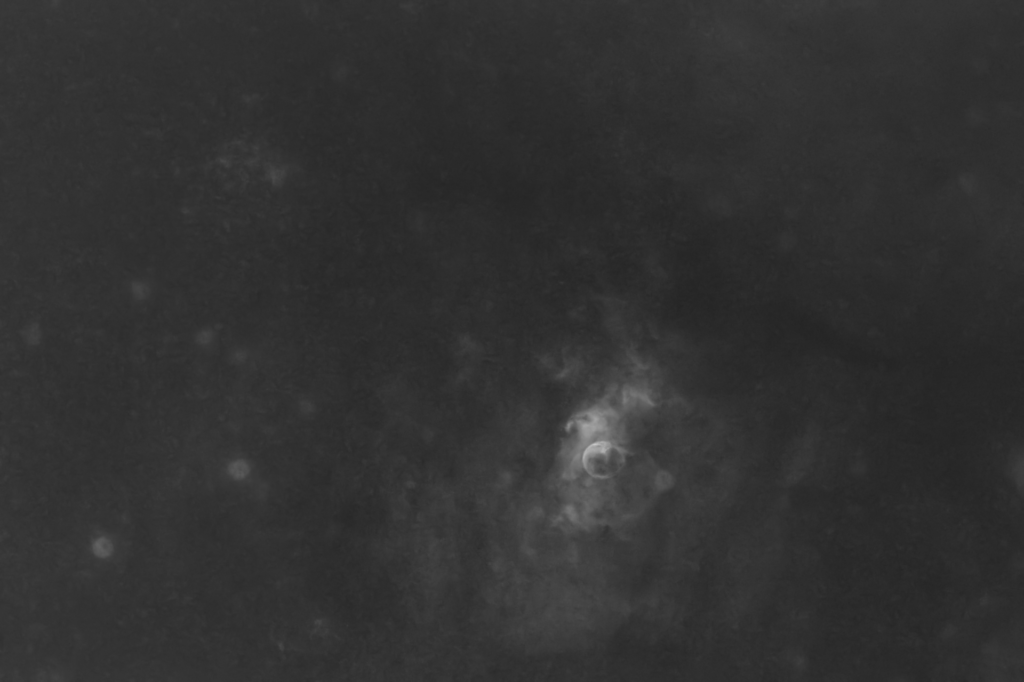


The gallery above shows some astrophotographs that have had their stars automatically removed using nox. nox is a neural network, trained exclusively on an artifical training dataset, which I have created. nox is otherwise based on StarNet as it shares almost the same architecture, and was trained using the same losses.
I can think of three good reasons to remove the stars from an astrophotograph:
- For art: Stars can be a distraction, and so starless images emphasise the nebulosity and are usually highly dramatic and pleasing to look at.
- For processing: Stars can be removed to allow nebulosity and other faint details to be enhanced without bloating the stars, which can be added back in later.
- For accurate star masks: Isolating stars allows the creation of star masks without any areas of nebulosity creeping in. (Accurate star masks are useful for various reasons, including, selective processing to enhance faint details; assessing and removing background noise and light pollution; color calibration; etc.)
Unfortunately, manually removing stars is difficult, highly labor intensive, and subjective decisions need to be made about how to fill the areas previously occupied by stars.
StarNet
Mikita (Nikita) Misiura developed StarNet, which is a deep convolutional neural network to automatically remove stars from astrophotographs. Mikita developed the model’s architecture, the training technique with adversarial and perceptual losses, and spent many hundreds of hours manually removing stars from astrophotographs to create a training dataset.
Architecture
The StarNet architecture is a convolutional encoder-decoder residual network. This is a powerful architecture for image noise reduction, super resolution, inpainting, and so on, and is well-studied in computer vision and image processing (see here, for example). It is also an architecture type that I have used before for noise reduction in astrophotography, and so I have some familarity and experience with it.
In short, a convolutional neural network (CNN) uses successive filter layers that slide along inputs to provide responses known as feature maps.
Encoder-decoder CNNs first encode the input as a “hidden” representation by passing it through a series of convolutional (filter) layers. They then decode the hidden representation to generate the output by passing it through another series of deconvolutional layers. Encoder-decoder networks essentially translate one image to another, passing it through a hidden numerical representations along the way.
Residual networks (ResNets) are a specific type of neural network in which there is a direct connection from the input to the output (and sometimes between other layers too). This is called a “skip connection”. In a sense, they compute the difference (the “residual”) between the input and the desired output. This simple idea allows more complex (deeper) neural networks with many layers to be trained to solve complex tasks. Before ResNets were introduced (in 2015), adding more layers made networks more difficult to train and degraded their accuracy.
The StarNet generator network has 16 convolutional/deconvolutional layers. The generator is the network that translates a starry image into a starless one. In addition, StarNet has a discriminator network (with 10 layers), which learns to distinguish “fake” starless images (created by the generator) from “true” starless (“ground truth”) images (ones created manually, for instance).
Mikita has made the architecture and training code publicly available on github, here. It is licensed under the MIT License, which grants permission, free of charge, to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, provided the copyright notice accompanies copies or substantial portions of the Software.
Training
StarNet was trained using adversarial and perceptual losses. Adversarial losses come from the discriminator. The discriminator is trained in parallel with the generator to identify fake starless images. Every training iteration, both a generated starless image (from the generator) and a ground truth starless version of the same starry image are fed into the discriminator. It is more complex than this, but the principle is that if the discriminator believes the generated image is fake, this generates a high generator “cost”, and vice versa. As training proceeds, attempting to reduce the cost, the discriminator gets better at identifying fake images, but the generator also gets better at creating convincing fake images. The generator and discriminator face off against each other in an arms race until the generator is so good that the discriminator is effectively just guessing and is only correct 50% of the time on average. It is a highly effective training technique.
In addition, StarNet training uses perceptual losses. The idea with perceptual losses is that generated images should look natural and tell us if two images look like each other to a human, even if there are mathematical differences (like an offset, or small-scale variation). StarNet achieves this by using the discriminator to compare the generated and ground truth images at different scales, weighting the different scales according to importance to perception.
show lessnox
In my recent work, I have developed a version of StarNet, which I am calling nox. It is based on a different training dataset, and uses a very similar architecture to StarNet; however, I use Layer Normalization between layers instead of Batch Normalization since it improves training rate and stability for me. I have independently written my own training and inference code (it is largely an adaptation of a previous machine learning project), only copying the StarNet architecture and the specific code for calculating adversarial and perceptual losses from the StarNet code on github.
I wanted to achieve my own star removal capability to feed into my other astrophotography processing work, with my own weights trained from initialization, and with enhanced capability to remove stars in cases where StarNet did not see many training images (e.g., different optical systems, images with dense star fields which are hard to manually remove stars from).
Artificial training dataset
It is commonly said in the field of machine learning that 25% of the work is in developing the architecture, and the remaining 75% is in creating the dataset. I’m sure Mikita would agree…
I just didn’t have the patience to remove stars manually to create a dataset, and figured it would be easier to add artificial but representative stars onto any random ground truth image. I added artificial stars to images from the SIDD and RENOIR datasets (which I happened to have to hand). These form training pairs in which the starry image is the input, and the original image with no stars is the desired output.
I used the Astropy and Photutils Python libraries and simulated various optical system parameters (arcseconds per pixel, FWHM, diffraction spikes), and atmospheric qualities (profile parameters, stability, noise). I also used the trend of the local luminosity function to get a realistic spread of star brightness versus frequency (brightness versus the number density logarithm is a triangular distribution).
Here are some grayscale examples (I am still working on the color version):




nox training
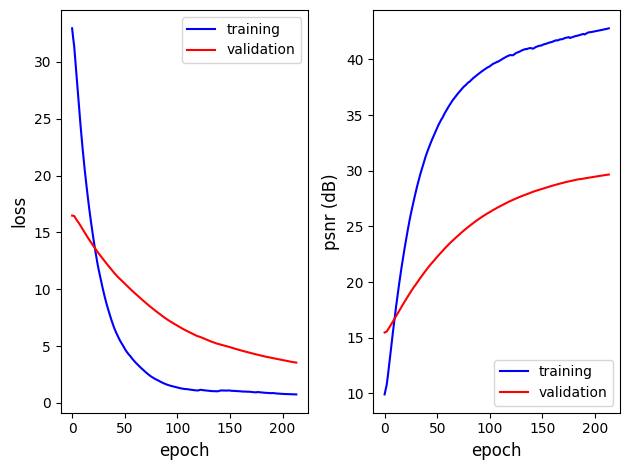
I generated 2500 random 512×512 training images pairs, and split the dataset 80:20 for training and validation respectively. I trained the network from initialization on an Nvidia Jetson AGX Orin (which includes a 2048-core Nvidia Ampere architecture GPU with 64 Tensor cores) using a batch size of 4 (batch size limited by memory). Training used a generator training rate of  throughout. Here are the loss and PSNR histories after 213 epochs, towards the end of the training:
throughout. Here are the loss and PSNR histories after 213 epochs, towards the end of the training:
nox performance
Since the network takes 512×512 tiles as input, images first must be decomposed into tiles before they can be destarred. To avoid edge artefacts, my code discards a 192-pixel wide border around every tile after destarring, so therefore the input tiles must overlap. This is equivalent to a stride of 128 pixels. After destarring, the tiles with discarded borders are reassembled.
Some inference examples are shown above using real astrophotographs (that were unseen during training since training uses artifical data only). Click an image to expand, view and scroll in Gallery Mode with captions.
Next steps
This Python implementation is really just a development code and not suitable for deployment. nox will be a tool in my astrophotography processing sofware, Hera. The model and weights will be converted into an OpenCV deep neural network (DNN) object and compiled into the Hera binaries. Within the Hera software, it will be available as a free-to-use image processing tool in its own right, and will also be built into other tools, for example, the star masking tool.
Before doing this, however, I will also develop a color dataset to train a color version of nox to remove stars from color images.
Python code
Generating training pairs
This code generates 2500 image pairs, dividing the work between 10 CPUs running in parallel. You can adjust these numbers to your preference. You will also need to have downloaded the SIDD and RENOIR datasets and installed the relevant packages as per the imports.
import matplotlib.pyplot as plt
from matplotlib import interactive
interactive(True)
from astropy.modeling.models import Moffat2D
from photutils.datasets import (make_model_sources_image, make_random_models_table, make_gaussian_sources_image,
make_random_gaussians_table, apply_poisson_noise)
import numpy as np
import sys
import pathlib
import os
import glob
import cv2
from threading import Thread
save_dir = os.getcwd() + os.sep + "nox data" + os.sep
cpus = 10
imcount = 2500
start = 0
preview_pairs = False # generate side-by-side image pairs for previewing
def get_images_paths(root_dir_ssid, root_dir_mi):
starless_lst = []
original_lst = []
# SSID dataset image paths
root = pathlib.Path(root_dir_ssid)
img_paths = list(root.rglob("*.PNG*"))
img_paths_lst = [str(path) for path in img_paths]
for p in img_paths_lst:
img_type = p.split(os.sep)[-1].split('_')[-3]
if img_type == "NOISY":
original_lst.append(p)
starless_lst.append(p)
elif img_type == "GT":
original_lst.append(p)
starless_lst.append(p)
# RENOIR dataset image paths
for p in [x[0] for x in os.walk(root_dir_mi)]:
noisyImgs = glob.glob(p + os.sep + '*Noisy.bmp')
original_lst.extend(noisyImgs)
starless_lst.extend(noisyImgs)
refImag = glob.glob(p + os.sep + '*Reference.bmp')
original_lst.extend(refImag)
starless_lst.extend(refImag)
original_array = np.asarray(original_lst)
starless_array = np.asarray(starless_lst)
return original_array, starless_array
def get_random_crop(image, label, crop_height, crop_width):
max_x = image.shape[1] - crop_width
max_y = image.shape[0] - crop_height
x = np.random.randint(0, max_x)
y = np.random.randint(0, max_y)
image_crop = image[y: y + crop_height, x: x + crop_width]
label_crop = label[y: y + crop_height, x: x + crop_width]
return image_crop, label_crop
def midtones(x, s, m):
y = np.clip(x, a_min = s, a_max = None) # set all less than s to s
y = (y - s)/(1. - s); # image from 0 to 1 after clipping
y = (m - 1.)*y/((2.*m - 1.)*y - m); # midtones transfer function (m = 0.5 for unity)
return y
def add_stars(image, label):
starModel = Moffat2D()
shape = image.shape[0:2]
app = np.random.uniform(low = 0.8, high = 2.2) # arcseconds per pixel, constant per image
FWHM0 = np.random.triangular(left = 1.8, mode = 2.5, right = 3.2)/app # random FWHM in pixels, constant per image
m = np.random.uniform(low = 0.01, high = 0.1) # midtones stretch value
gain = np.random.uniform(low = 0.1, high = 2.)
starblur = np.random.uniform(low = 0., high = 3.)
# middle-sized stars (large enough for a properly resolved source function, not large enough for bloat) with some midtones transformation
n_src = 300
param_ranges = {'amplitude': [1., 1.], 'x_0': [0, shape[1]], 'y_0': [0, shape[0]], 'gamma': [1., 1.], 'alpha': [2.0, 10]} # for range of alpha, see https://academic.oup.com/mnras/article/328/3/977/1247204 ('beta' in reference)
sources = make_random_models_table(n_src, param_ranges, seed = None)
sources['amplitude'] = np.multiply(np.power(10., np.random.triangular(left = 0., mode = 0., right = 1., size = n_src)) - 1., 3./9) # replace amplitudes with triangular distribution of magnitudes following trend of local luminosity function, resulting in range 0 to 3
sources['gamma'] = FWHM0/2./np.sqrt(pow(2., 1./sources['alpha']) - 1.) # calcuate gamma according to alpha and FWHM
stars1 = make_model_sources_image(shape, starModel, sources)
stars1 = apply_poisson_noise(stars1*255*gain, seed=None)/255/gain # add Poisson noise
stars1 = midtones(stars1, 0., m)
stars1 = cv2.GaussianBlur(stars1, (0, 0), starblur)
theta0 = np.random.uniform(0, np.pi/2)
yes_no_spikes = np.random.randint(2)
if yes_no_spikes:
sources['amplitude'] = np.clip(sources['amplitude'], 0., 1.) # cap amplitude at 1. for adding spikes
stars1 = add_spikes(stars1, sources, theta0)
# large stars - large enough for full-well capacity bleeding / bloating
n_large = 20
param_ranges = {'amplitude': [1., 1.], 'x_0': [0, shape[1]], 'y_0': [0, shape[0]], 'gamma': [1., 1.], 'alpha': [2.0, 10]} # for range of alpha, see https://academic.oup.com/mnras/article/328/3/977/1247204 ('beta' in reference)
sources = make_random_models_table(n_large, param_ranges)
sources['amplitude'] = np.multiply(np.power(10., np.random.triangular(left = 0., mode = 0., right = 1., size = n_large)) - 1., 1./9) + 1. # replace amplitudes with triangular distribution of magnitudes following trend of local luminosity function, resulting in range 1 to 2
FWHM = np.random.triangular(left = FWHM0, mode = FWHM0, right = 15., size = n_large) # use range of wide FWHMs to simulate full-well capacity bleeding / bloating
sources['gamma'] = FWHM/2./np.sqrt(pow(2., 1./sources['alpha']) - 1.) # calcuate gamma according to alpha and FWHM
stars2 = make_model_sources_image(shape, starModel, sources)
stars2 = apply_poisson_noise(stars2*255*gain, seed=None)/255/gain # add Poisson noise
stars2 = midtones(stars2, 0., m)
stars2 = cv2.GaussianBlur(stars2, (0, 0), starblur)
if yes_no_spikes: stars2 = add_spikes(stars2, sources, theta0)
# small and dim Gaussian stars - subject to a bit more 'wobble'
n_small = 2500
stretch_range = 1.1 # range of star 'smearing'
param_ranges = {'amplitude': [1., 1.], 'x_mean': [0, shape[1]], 'y_mean': [0, shape[0]], 'x_stddev': [1., 1.], 'y_stddev': [1., 1.], 'theta': [0., np.pi]}
sources = make_random_gaussians_table(n_small, param_ranges, seed = None)
sources['amplitude'] = np.multiply(np.power(10., np.random.triangular(left = 0., mode = 0., right = 1., size = n_small)) - 1., 0.1/9) # replace amplitudes with triangular distribution of magnitudes following trend of local luminosity function, resulting in range 0 to 0.1
xstretch = np.random.uniform(low = 1./stretch_range, high = stretch_range) # generate uniform distribution of FWHM x stretch factors
ystretch = np.random.uniform(low = 1./stretch_range, high = stretch_range) # generate uniform distribution of FWHM x stretch factors
sources['x_stddev'] = np.multiply(FWHM0/2.35, xstretch)
sources['y_stddev'] = np.multiply(FWHM0/2.35, ystretch)
stars3 = make_gaussian_sources_image(shape, sources)
stars3 = apply_poisson_noise(stars3*255*gain, seed=None)/255/gain # add Poisson noise
stars3 = midtones(stars3, 0., m)
stars3 = cv2.GaussianBlur(stars3, (0, 0), starblur)
# combine stars to image
stars = stars1 + stars2 + stars3
image = 1. - (1. - stars)*(1. - image) # screen blend stars
image = np.clip(image, 0., 1.)
return image, label
def add_spikes(stars, sources, theta0): # add simulated diffraction spikes
FWHM = 2.*sources['gamma']*np.sqrt(pow(2., 1./sources['alpha']) - 1.)
n_src = len(sources['amplitude'])
shape = stars.shape
sources['x_mean'] = sources['x_0']
del sources['x_0']
sources['y_mean'] = sources['y_0']
del sources['y_0']
del sources['gamma']
del sources['alpha']
sources['amplitude'] = np.multiply(sources['amplitude'], np.random.uniform(low = 0.8, high = 1.0, size = n_src))
sources['x_stddev'] = np.multiply(np.multiply(FWHM, sources['amplitude']/15), np.random.uniform(low = 1., high = 1.2, size = n_src))
sources['y_stddev'] = np.multiply(np.multiply(FWHM, sources['amplitude']), np.random.uniform(low = 1., high = 1.5, size = n_src))
sources['theta'] = np.ones(n_src)*theta0
spikes = make_gaussian_sources_image(shape, sources)
sources['theta'] = sources['theta'] + np.pi/2
spikes += make_gaussian_sources_image(shape, sources)
spikes = np.clip(spikes, 0., 1.)
spikes = cv2.GaussianBlur(spikes, (0, 0), np.random.uniform(low = 0.5, high = 1.0))
return 1. - (1. - stars)*(1. - spikes) # screen blend spikes
def create_images(images, labels, i_from, i_to):
for i in range(i_from, i_to):
print('image %d'%i)
if os.path.exists(save_dir + 'x%d.png'%i) and os.path.exists(save_dir + 'y%d.png'%i): continue
image = cv2.imread(images[i%len(images)])
label = cv2.imread(labels[i%len(labels)])
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)/255.
label = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)/255.
image, label = get_random_crop(image, label, 512, 512)
image, label = add_stars(image, label)
cv2.imwrite(save_dir + 'x%d.png'%i, cv2.cvtColor(np.float32(image)*255., cv2.COLOR_GRAY2BGR))
cv2.imwrite(save_dir + 'y%d.png'%i, cv2.cvtColor(np.float32(label)*255., cv2.COLOR_GRAY2BGR))
if preview_pairs:
# plot training images
plt.close()
fig, ax = plt.subplots(1, 2, sharex = True, figsize=(21, 21))
ax[0].imshow(cv2.cvtColor(np.float32(image), cv2.COLOR_GRAY2BGR))
ax[0].set_axis_off()
ax[1].imshow(cv2.cvtColor(np.float32(label), cv2.COLOR_GRAY2BGR))
ax[1].set_axis_off()
fig.tight_layout()
plt.savefig(save_dir + '%i.png'%i, bbox_inches = 'tight')
if __name__ == "__main__":
images, labels = get_images_paths("../datasets/SIDD_Small_sRGB_Only", "../datasets/RENOIR")
# shuffle
training_data = list(zip(images, labels))
np.random.shuffle(training_data)
images, labels = zip(*training_data)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
if not preview_pairs:
images_per_cpu = int((imcount - start)/cpus)
threads = []
for cpu in range(cpus):
thread = Thread(target = create_images, args = (images, labels, start + cpu*images_per_cpu, start + (cpu + 1)*images_per_cpu))
threads.append(thread)
threads[-1].start()
for i in range(len(threads)):
threads[i].join()
print('joined thread %i'%i)
else: create_images(images, labels, 0, imcount) # matplotlib only runs in main thread
Training and inference
This code can be run in two modes:
- Training mode (“python ./nox.py train”)
- Inference mode (“python ./nox.py infer input.tiff”) and it will output a file “starless.png” in the current working directory.
You will need to have installed Tensorflow and various other Python packages, as per the imports. Note that the input and output image formats do not necessarily need to be tiff and png, respectively.
import sys
import pathlib
import os
import numpy as np
import cv2
import skimage
from sklearn.model_selection import train_test_split
import glob
import matplotlib.pyplot as plt
from matplotlib import interactive
interactive(True)
import pickle
import gc
import csv
import time
import tensorflow as tf
import pandas as pd
# enable dynamic memory allocation
gpu_devices = tf.config.experimental.list_physical_devices('GPU')
for device in gpu_devices:
tf.config.experimental.set_memory_growth(device, True)
# global variables
epochs = 1500
n_channels = 1
patch_size = 512
stride = 128
border = int((patch_size - stride)/2)
print('border = ' + str(border))
# training parameters
BATCH_SIZE = 4 # number of training samples to work through before the model’s parameters are updated
ema = 0.9999 # exponential moving average: keep 99.99% of the existing state and 0.01% of the new state
lr = 1e-4 # learning rate
save_backups = True
validation = True
def generator():
tf.keras.backend.clear_session() # release global state of old models and layers
layers = []
filters = [64, 128, 256, 512, 512, 512, 512, 512, 512, 512, 512, 512, 256, 128, 64] # filter layers 0 - 14
input = tf.keras.layers.Input(shape = (patch_size, patch_size, n_channels), name = "gen_input_image")
for i in range(1 + len(filters)):
if i == 0: # layer 0
convolved = tf.keras.layers.Conv2D(filters[0], kernel_size = 4, strides = (2, 2), padding = "same", kernel_initializer = tf.initializers.GlorotUniform())(input)
layers.append(convolved)
elif 1 <= i <= 7: # convolution layers
rectified = tf.keras.layers.LeakyReLU(alpha = 0.2)(layers[-1])
convolved = tf.keras.layers.Conv2D(filters[i], kernel_size = 4, strides = (2, 2), padding = "same", kernel_initializer = tf.initializers.GlorotUniform())(rectified)
normalized = tf.keras.layers.LayerNormalization()(convolved)
layers.append(normalized)
elif 8 <= i <= 14: # deconvolution layers
if i == 8:
rectified = tf.keras.layers.ReLU()(layers[-1])
else:
concatenated = tf.concat([layers[-1], layers[15 - i]], axis = 3)
rectified = tf.keras.layers.ReLU()(concatenated)
deconvolved = tf.keras.layers.Conv2DTranspose(filters[i], kernel_size = 4, strides = (2, 2), padding = "same", kernel_initializer = tf.initializers.GlorotUniform())(rectified)
normalized = tf.keras.layers.LayerNormalization()(deconvolved)
layers.append(normalized)
else: # layer 15
concatenated = tf.concat([layers[-1], layers[0]], axis = 3)
rectified = tf.keras.layers.ReLU()(concatenated)
deconvolved = tf.keras.layers.Conv2DTranspose(n_channels, kernel_size = 4, strides = (2, 2), padding = "same", kernel_initializer = tf.initializers.GlorotUniform())(rectified)
rectified = tf.keras.layers.ReLU()(deconvolved)
output = tf.math.subtract(input, rectified)
return tf.keras.Model(inputs = input, outputs = output, name = "generator")
def discriminator():
layers = []
filters = [32, 64, 64, 128, 128, 256, 256, 256, 8]
input = tf.keras.layers.Input(shape = (patch_size, patch_size, n_channels), name = "dis_input_image")
for i in range(1 + len(filters)):
if i % 2 == 1 or i == 8:
padding = "valid"
strides = (2, 2)
else:
padding = "same"
strides = (1, 1)
if i == 0: # layer 0
convolved = tf.keras.layers.Conv2D(filters[i], kernel_size = 3, strides = strides, padding = padding)(input)
rectified = tf.keras.layers.LeakyReLU(alpha = 0.2)(convolved)
layers.append(rectified)
elif 1 <= i <= 8: # convolution layers
convolved = tf.keras.layers.Conv2D(filters[i], kernel_size = 3, strides = strides, padding = padding)(layers[-1])
normalized = tf.keras.layers.LayerNormalization()(convolved)
rectified = tf.keras.layers.LeakyReLU(alpha = 0.2)(normalized)
layers.append(rectified)
else: # layer 9
dense = tf.keras.layers.Dense(1)(layers[-1])
sigmoid = tf.nn.sigmoid(dense)
layers.append(sigmoid)
output = [layers[0], layers[1], layers[2], layers[3], layers[4], layers[5], layers[6], layers[7], layers[-1]]
return tf.keras.Model(inputs = input, outputs = output, name = "discriminator")
def get_images_paths(root_dir):
starless_lst = []
original_lst = []
root = pathlib.Path(root_dir)
x_paths = sorted(list(root.rglob("x*.png*")))
y_paths = sorted(list(root.rglob("y*.png*")))
x_paths_lst = [str(path) for path in x_paths]
for p in x_paths_lst:
original_lst.append(p)
y_paths_lst = [str(path) for path in y_paths]
for p in y_paths_lst:
starless_lst.append(p)
original_array = np.asarray(original_lst)
starless_array = np.asarray(starless_lst)
return original_array, starless_array
def up_down_flip(image, label):
if tf.random.uniform(shape = [], minval = 0, maxval = 2, dtype = tf.int32) == 1:
image = tf.image.flip_up_down(image)
label = tf.image.flip_up_down(label)
return image, label
def left_right_flip(image, label):
if tf.random.uniform(shape = [], minval = 0, maxval = 2, dtype = tf.int32) == 1:
image = tf.image.flip_left_right(image)
label = tf.image.flip_left_right(label)
return image, label
def rotate_90(image, label):
rand_value = tf.random.uniform(shape = [], minval = 0, maxval = 4, dtype = tf.int32)
image = tf.image.rot90(image, rand_value)
label = tf.image.rot90(label, rand_value)
return image, label
def adjust_brightness(image, label):
if tf.random.uniform(shape = []) < 0.7:
m = tf.math.minimum(image, label)
offset = tf.random.uniform(shape = [])*0.25 - tf.random.uniform(shape = [])*m
image = image + offset*(1. - image)
label = label + offset*(1. - label)
image = tf.clip_by_value(image, 0. , 1.)
label = tf.clip_by_value(label, 0. , 1.)
return image, label
def process_path(path_original, path_starless):
img_original = tf.io.read_file(path_original)
img_original = tf.io.decode_image(img_original, dtype = tf.dtypes.float32)
img_starless = tf.io.read_file(path_starless)
img_starless = tf.io.decode_image(img_starless, dtype = tf.dtypes.float32)
if n_channels == 1:
img_original = tf.image.rgb_to_grayscale(img_original)
img_starless = tf.image.rgb_to_grayscale(img_starless)
return img_original, img_starless
def random_crop(image, label):
combined = tf.concat([image, label], axis=2)
combined_crop = tf.image.random_crop(combined, [patch_size, patch_size, n_channels*2])
return (combined_crop[:, :, :n_channels], combined_crop[:, :, n_channels:])
def data_generator(X, y, batch_size, augmentations = None):
dataset = tf.data.Dataset.from_tensor_slices((X, y))
dataset = dataset.shuffle(buffer_size = 100, reshuffle_each_iteration = True)
dataset = dataset.map(process_path, num_parallel_calls = tf.data.AUTOTUNE)
# dataset = dataset.map(random_crop, num_parallel_calls = tf.data.AUTOTUNE) # uncomment if dataset tiles are oversized
if augmentations:
for f in augmentations:
dataset = dataset.map(f, num_parallel_calls = tf.data.AUTOTUNE)
dataset = dataset.repeat() # re-initialize the dataset as soon as all the entries have been read
dataset = dataset.batch(batch_size = batch_size, drop_remainder = True) # make batches out of dataset
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE) # allows later elements to be prepared while the current element is being processed, improving latency and throughput, at the cost of using additional memory to store prefetched elements
return dataset
def PSNR(y_true, y_pred):
return tf.image.psnr(y_pred, y_true, max_val = 1.)
def inference_single_tile(model, original_image):
input_image = np.expand_dims(original_image, axis = 0)
predicted_image = (model.predict(input_image*2. - 1.) + 1.)/2.
return predicted_image[0]
def inference_batch_tiles(model, original_images):
predicted_images = (model.predict(original_images*2. - 1., batch_size = BATCH_SIZE) + 1.)/2.
return predicted_images
def infer_image(model, original_image, border = 0):
predicted_image = np.zeros(original_image.shape)
sizeX = original_image.shape[1]
sizeY = original_image.shape[0]
# add border around original image
original_image = cv2.copyMakeBorder(original_image, border, border, border, border, cv2.BORDER_REFLECT)
sizeX = original_image.shape[1]
sizeY = original_image.shape[0]
# split original image into tiles
fromRow = 0 # row pixel index
fromCol = 0 # col pixel index
nRows = 0
nCols = 0
original_lst = []
finalRow = False
while True: # loop rows
nRows += 1
toRow = fromRow + patch_size
if toRow >= sizeY:
fromRow = sizeY - patch_size
toRow = sizeY
finalRow = True
finalCol = False
while True: # loop cols
if finalRow:
nCols += 1 # count columns on final row only
toCol = fromCol + patch_size
if toCol >= sizeX:
fromCol = sizeX - patch_size
toCol = sizeX
finalCol = True
original_roi = original_image[fromRow:toRow, fromCol:toCol]
original_lst.append(original_roi)
if finalCol:
fromCol = 0
break
else:
fromCol += (patch_size - 2*border)
if finalRow:
break
else:
fromRow += (patch_size - 2*border)
# infer batch of tiles
original_rois = np.array(original_lst)
predicted_rois = inference_batch_tiles(model, original_rois)
# build up predicted image from predicted tiles
fromRow = 0 # row pixel index
fromCol = 0 # col pixel index
count = 0
for i in range(0, nRows):
toRow = fromRow + patch_size - 2*border
if i == nRows - 1:
fromRow = (sizeY - 2*border) - (patch_size - 2*border)
toRow = (sizeY - 2*border)
finalRow = True
for j in range(0, nCols):
toCol = fromCol + patch_size - 2*border
if j == nCols - 1:
fromCol = (sizeX - 2*border) - (patch_size - 2*border)
toCol = (sizeX - 2*border)
finalCol = True
predicted_image[fromRow:toRow, fromCol:toCol] = predicted_rois[count][border:patch_size - border, border:patch_size - border]
count = count + 1
if j == nCols - 1:
fromCol = 0
break
else:
fromCol += (patch_size - 2*border)
fromRow += (patch_size - 2*border)
np.clip(predicted_image, 0., 1., predicted_image) # clip 0 to 1
return predicted_image
def infer(file = ''):
tf.keras.backend.clear_session()
print('building generator...')
model = generator()
model.summary()
if os.path.exists(os.getcwd() + os.sep + 'generator_gray.h5'):
print('loading weights...')
model.load_weights('generator_gray.h5')
else: return
# process image from disk
if len(file) > 0 and os.path.exists(file):
original_image = cv2.imread(file)
if len(original_image.shape) == 3:
original_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB)
if n_channels == 1:
original_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2GRAY)
original_image = original_image[:, :, np.newaxis]
if original_image.dtype == 'uint8': original_image = original_image/255.
cv2.imwrite('starry.png', np.float32(original_image)*255.)
start_time = time.time()
starless_image = infer_image(model, original_image, border = border) # infer
print("--- %s seconds ---" % (time.time() - start_time))
cv2.imwrite('starless.png', np.float32(starless_image)*255.)
else: # process image from dataset
original_array_paths, starless_array_paths = get_images_paths(os.getcwd() + os.sep + "nox data") # training and test image paths
i = np.random.randint(0, original_array_paths.shape[0]) # get a random noisy image index
original_image = cv2.imread(original_array_paths[i])
if n_channels == 1:
original_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2GRAY)
original_image = original_image[:, :, np.newaxis]
cv2.imwrite('input.png', original_image)
if n_channels == 3: original_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB)
if original_image.dtype == 'uint8': original_image = original_image/255.
gt_image = cv2.imread(starless_array_paths[i])
if n_channels == 1:
gt_image = cv2.cvtColor(gt_image, cv2.COLOR_BGR2GRAY)
gt_image = gt_image[:, :, np.newaxis]
cv2.imwrite('gt.png', gt_image)
if n_channels == 3: gt_image = cv2.cvtColor(gt_image, cv2.COLOR_BGR2RGB)
if gt_image.dtype == 'uint8': gt_image = gt_image/255.
predicted_image = infer_image(model, original_image, border) # infer
cv2.imwrite('output.png', cv2.cvtColor(np.float32(predicted_image)*255., cv2.COLOR_RGB2BGR))
psnr1 = PSNR(original_image, gt_image).numpy()
psnr2 = PSNR(predicted_image, gt_image).numpy()
print('PSNR(original, gt) = ' + str(psnr1))
print('PSNR(starless, gt) = ' + str(psnr2))
def train():
tf.keras.backend.clear_session()
# training and test image paths
original_array_paths, starless_array_paths = get_images_paths(os.getcwd() + os.sep + "nox data")
if validation:
original_train_paths, original_test_paths, starless_train_paths, starless_test_paths = train_test_split(original_array_paths, starless_array_paths, test_size = 0.2, random_state = 42)
print('number of original images for training = ' + str(original_train_paths.shape))
print('number of original images for testing = ' + str(original_test_paths.shape))
print('number of starless images for training = ' + str(starless_train_paths.shape))
print('number of starless images for testing = ' + str(starless_test_paths.shape))
else:
original_train_paths = original_array_paths
starless_train_paths = starless_array_paths
print('number of original images for training = ' + str(original_train_paths.shape))
print('number of starless images for training = ' + str(starless_train_paths.shape))
# data generators
augmentation_lst = [up_down_flip, left_right_flip, rotate_90, adjust_brightness]
image_generator_train = data_generator(X = original_train_paths, y = starless_train_paths, batch_size = BATCH_SIZE, augmentations = augmentation_lst)
image_generator_test = []
if validation:
image_generator_test = data_generator(X = original_test_paths, y = starless_test_paths, batch_size = BATCH_SIZE)
# nets
print('building generator...')
G = generator()
G.summary()
print('building discriminator...')
D = discriminator()
D.summary()
# optimizers
gen_optimizer = tf.optimizers.Adam(learning_rate = lr)
dis_optimizer = tf.optimizers.Adam(learning_rate = lr/4)
# number of epochs and steps
print('number of training epochs = ' + str(epochs))
steps_per_epoch_train = int(len(original_train_paths)/BATCH_SIZE)
print('steps per training epoch = ' + str(steps_per_epoch_train))
steps_per_epoch_validation = 1
if validation:
steps_per_epoch_validation = int(len(original_test_paths)/BATCH_SIZE)
print('steps per validation epoch = ' + str(steps_per_epoch_validation))
hist_train = {}
hist_val = {}
# load weights
e0 = -1
if os.path.exists(os.getcwd() + os.sep + 'generator_gray.h5') \
and os.path.exists(os.getcwd() + os.sep + 'discriminator_gray.h5') \
and os.path.exists(os.getcwd() + os.sep + 'history.pkl'):
print('loading weights...')
G.load_weights('generator_gray.h5')
D.load_weights('discriminator_gray.h5')
with open('history.pkl', 'rb') as f:
print('loading training history...')
if validation:
e0, hist_train, hist_val = pickle.load(f)
print("\repoch %d: loss %f PSNR %f val: loss %f PSNR %f \n"%(e0, hist_train['total'][-1], hist_train['psnr'][-1], hist_val['total'][-1], hist_val['psnr'][-1]), end = '')
else:
e0, hist_train = pickle.load(f)
print("\repoch %d: loss %f PSNR %f \n"%(e0, hist_train['total'][-1], hist_train['psnr'][-1]), end = '')
# training epochs with validation
# START: This portion of code is Copyright (c) 2018-2019 Nikita Misiura and used here under the MIT License
for e in range(e0 + 1, epochs, 1):
# training batches
for i in range(steps_per_epoch_train):
x, y = image_generator_train.take(1).as_numpy_iterator().next()
x = x*2. - 1. # rescale fom -1 to 1
y = y*2. - 1.
if i>0:
print("\repoch %d: it %d / %d loss %f PSNR %f "%(e, i + 1, steps_per_epoch_train, hist_train['total'][-1], hist_train['psnr'][-1]), end = '')
else:
print("\repoch %d: it %d / %d "%(e, i + 1, steps_per_epoch_train), end = '')
with tf.GradientTape() as gen_tape, tf.GradientTape() as dis_tape:
gen_output = G(x, training = True)
p1_real, p2_real, p3_real, p4_real, p5_real, p6_real, p7_real, p8_real, predict_real = D(y, training = True)
p1_fake, p2_fake, p3_fake, p4_fake, p5_fake, p6_fake, p7_fake, p8_fake, predict_fake = D(gen_output, training = True)
d = {}
dis_loss = tf.reduce_mean(-(tf.math.log(predict_real + 1E-8)+tf.math.log(1. - predict_fake + 1E-8)))
d['dis_loss'] = dis_loss
gen_loss_GAN = tf.reduce_mean(-tf.math.log(predict_fake + 1E-8))
d['gen_loss_GAN'] = gen_loss_GAN
gen_p1 = tf.reduce_mean(tf.abs(p1_fake - p1_real))
d['gen_p1'] = gen_p1
gen_p2 = tf.reduce_mean(tf.abs(p2_fake - p2_real))
d['gen_p2'] = gen_p2
gen_p3 = tf.reduce_mean(tf.abs(p3_fake - p3_real))
d['gen_p3'] = gen_p3
gen_p4 = tf.reduce_mean(tf.abs(p4_fake - p4_real))
d['gen_p4'] = gen_p4
gen_p5 = tf.reduce_mean(tf.abs(p5_fake - p5_real))
d['gen_p5'] = gen_p5
gen_p6 = tf.reduce_mean(tf.abs(p6_fake - p6_real))
d['gen_p6'] = gen_p6
gen_p7 = tf.reduce_mean(tf.abs(p7_fake - p7_real))
d['gen_p7'] = gen_p7
gen_p8 = tf.reduce_mean(tf.abs(p8_fake - p8_real))
d['gen_p8'] = gen_p8
gen_L1 = tf.reduce_mean(tf.abs(y - gen_output))
d['gen_L1'] = gen_L1*100.
d['psnr'] = tf.reduce_mean(PSNR(y, gen_output))
gen_loss = gen_loss_GAN*0.1 + gen_p1*0.1 + gen_p2*10. + gen_p3*10. + gen_p4*10. + gen_p5*10. + gen_p6*10. + gen_p7*10. + gen_p8*10. + gen_L1*100.
d['total'] = gen_loss
for k in d:
if k in hist_train.keys():
hist_train[k].append(d[k]*(1. - ema) + hist_train[k][-1]*ema)
else:
hist_train[k] = [d[k]]
gen_grads = gen_tape.gradient(gen_loss, G.trainable_variables)
gen_optimizer.apply_gradients(zip(gen_grads, G.trainable_variables))
dis_grads = dis_tape.gradient(dis_loss, D.trainable_variables)
dis_optimizer.apply_gradients(zip(dis_grads, D.trainable_variables))
# validation batches
if validation:
for i in range(steps_per_epoch_validation):
x, y = image_generator_test.take(1).as_numpy_iterator().next()
x = x*2. - 1. # rescale fom -1 to 1
y = y*2. - 1.
if i > 0:
print("\repoch %d: loss %f PSNR %f val: it %d / %d loss %f PSNR %f "%(e, hist_train['total'][-1], hist_train['psnr'][-1], i+1, steps_per_epoch_validation, hist_val['total'][-1], hist_val['psnr'][-1]), end = '')
else:
print("\repoch %d: loss %f PSNR %f val: it %d / %d "%(e, hist_train['total'][-1], hist_train['psnr'][-1], i+1, steps_per_epoch_validation), end = '')
gen_output = G(x)
p1_real, p2_real, p3_real, p4_real, p5_real, p6_real, p7_real, p8_real, predict_real = D(y)
p1_fake, p2_fake, p3_fake, p4_fake, p5_fake, p6_fake, p7_fake, p8_fake, predict_fake = D(gen_output)
d = {}
dis_loss = tf.reduce_mean(-(tf.math.log(predict_real + 1E-8) + tf.math.log(1. - predict_fake + 1E-8)))
d['dis_loss'] = dis_loss
gen_loss_GAN = tf.reduce_mean(-tf.math.log(predict_fake + 1E-8))
d['gen_loss_GAN'] = gen_loss_GAN
gen_p1 = tf.reduce_mean(tf.abs(p1_fake - p1_real))
d['gen_p1'] = gen_p1
gen_p2 = tf.reduce_mean(tf.abs(p2_fake - p2_real))
d['gen_p2'] = gen_p2
gen_p3 = tf.reduce_mean(tf.abs(p3_fake - p3_real))
d['gen_p3'] = gen_p3
gen_p4 = tf.reduce_mean(tf.abs(p4_fake - p4_real))
d['gen_p4'] = gen_p4
gen_p5 = tf.reduce_mean(tf.abs(p5_fake - p5_real))
d['gen_p5'] = gen_p5
gen_p6 = tf.reduce_mean(tf.abs(p6_fake - p6_real))
d['gen_p6'] = gen_p6
gen_p7 = tf.reduce_mean(tf.abs(p7_fake - p7_real))
d['gen_p7'] = gen_p7
gen_p8 = tf.reduce_mean(tf.abs(p8_fake - p8_real))
d['gen_p8'] = gen_p8
gen_L1 = tf.reduce_mean(tf.abs(y - gen_output))
d['gen_L1'] = gen_L1*100.
d['psnr'] = tf.reduce_mean(PSNR(y, gen_output))
gen_loss = gen_loss_GAN*0.1 + gen_p1*0.1 + gen_p2*10. + gen_p3*10. + gen_p4*10. + gen_p5*10. + gen_p6*10. + gen_p7*10. + gen_p8*10. + gen_L1*100.
d['total'] = gen_loss
for k in d:
if k in hist_val.keys():
hist_val[k].append(d[k]*(1. - ema) + hist_val[k][-1]*ema)
else:
hist_val[k] = [d[k]]
print("\repoch %d: loss %f PSNR %f val: loss %f PSNR %f \n"%(e, hist_train['total'][-1], hist_train['psnr'][-1], hist_val['total'][-1], hist_val['psnr'][-1]), end = '')
else:
print("")
# END: This portion of code is Copyright (c) 2018-2019 Nikita Misiura and used here under the MIT License
if save_backups:
G.save_weights('generator_gray.h5')
D.save_weights('discriminator_gray.h5')
if validation:
with open('history.pkl', 'wb') as f:
pickle.dump([e, hist_train, hist_val], f)
else:
with open('history.pkl', 'wb') as f:
pickle.dump([e, hist_train], f)
# CSV logger
with open('history.csv', 'a', newline = '') as csv:
if validation:
if e == 0: csv.write('epoch,loss,psnr,val_loss,val_psnr,lr_gen,lr\n')
csv.write('%d,%f,%f,%f,%f,%f\n'%
(e,
hist_train['total'][-1].numpy(),
hist_train['psnr'][-1].numpy(),
hist_val['total'][-1].numpy(),
hist_val['psnr'][-1].numpy(),
lr))
else:
if e == 0: csv.write('epoch,loss,psnr,lr\n')
csv.write('%d,%f,%f,%f\n'%
(e,
hist_train['total'][-1].numpy(),
hist_train['psnr'][-1].numpy(),
lr))
# plotting
if validation and os.path.exists('history.csv'):
df = pd.read_csv('history.csv')
fig, ax = plt.subplots(1, 2, sharex = True)#, figsize = (21, 21)
line1, = ax[0].plot(df.epoch, df.loss, 'b', label = 'training')
line2, = ax[0].plot(df.epoch, df.val_loss, 'r', label = 'validation')
ax[0].legend(handles=[line1, line2])
ax[0].set_xlabel('epoch', fontsize = 12)
ax[0].set_ylabel('loss', fontsize = 12)
line1, = ax[1].plot(df.epoch, df.psnr, 'b', label = 'training')
line2, ax[1].plot(df.epoch, df.val_psnr, 'r', label = 'validation')
ax[1].legend(handles = [line1, line2])
ax[1].set_xlabel('epoch', fontsize = 12)
ax[1].set_ylabel('psnr (dB)', fontsize = 12)
fig.tight_layout()
plt.savefig(os.getcwd() + os.sep + 'training.png', bbox_inches = 'tight')
elif ~validation and os.path.exists('history.csv'):
df = pd.read_csv('history.csv')
fig, ax = plt.subplots(1, 2, sharex = True)#, figsize = (21, 21)
line1, = ax[0].plot(df.epoch, df.loss, 'b', label = 'training')
ax[0].legend(handles=[line1])
ax[0].set_xlabel('epoch', fontsize = 12)
ax[0].set_ylabel('loss', fontsize = 12)
line1, = ax[1].plot(df.epoch, df.psnr, 'b', label = 'training')
ax[1].legend(handles = [line1])
ax[1].set_xlabel('epoch', fontsize = 12)
ax[1].set_ylabel('psnr (dB)', fontsize = 12)
fig.tight_layout()
plt.savefig(os.getcwd() + os.sep + 'training.png', bbox_inches = 'tight')
if validation:
# process random image from data set
i = np.random.randint(0, original_array_paths.shape[0]) # get a random noisy image index
original_image = cv2.imread(original_array_paths[i])
if n_channels == 1:
original_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2GRAY)
original_image = original_image[:, :, np.newaxis]
cv2.imwrite('input.png', original_image)
if n_channels == 3: original_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB)
if original_image.dtype == 'uint8': original_image = original_image/255.
gt_image = cv2.imread(starless_array_paths[i])
if n_channels == 1:
gt_image = cv2.cvtColor(gt_image, cv2.COLOR_BGR2GRAY)
gt_image = gt_image[:, :, np.newaxis]
cv2.imwrite('gt.png', gt_image)
if n_channels == 3: gt_image = cv2.cvtColor(gt_image, cv2.COLOR_BGR2RGB)
if gt_image.dtype == 'uint8': gt_image = gt_image/255.
predicted_image = infer_image(G, original_image, border = border) # infer
cv2.imwrite('output.png', cv2.cvtColor(np.float32(predicted_image)*255., cv2.COLOR_RGB2BGR))
psnr1 = PSNR(original_image, gt_image).numpy()
psnr2 = PSNR(predicted_image, gt_image).numpy()
print('PSNR(input, gt) = ' + str(psnr1))
print('PSNR(output, gt) = ' + str(psnr2))
# housekeeping
gc.collect()
tf.keras.backend.clear_session()
if __name__ == "__main__":
mode = 'train' # train mode by default
if len(sys.argv) > 1: mode = sys.argv[1]
if mode == 'train': train()
elif mode == 'infer':
if len(sys.argv) > 2: infer(sys.argv[2]) # file name
else: infer() # draw randomly from dataset
MIT License
The relevant sections of this code, as indicated by comments, are used under the MIT License, as follows:
Code is Copyright (c) 2018-2019 Nikita Misiura
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
hide Python code